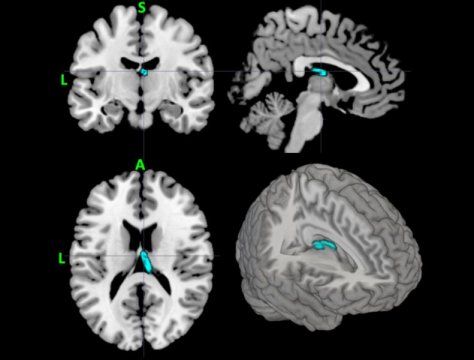
Teknoloji Psikologlar, depresyonu teşhis etmeye yardımcı olmak için makine öğrenimini istemektedirler 9 yıl ago Harun Antepli Tags: Depresyon Continue Reading Previous Yeni uluslararası bankacılık kuralları, başka bir finansal krizi engellemezNext Yeni 5G verici, önceki verilerden 20 kat daha verimli Daha Fazla Okuyun Batı Trakya Haber Dünya Kültür Sanat Medya Teknoloji Türkiye ve İngiltere, Ankara’nın Eurofighter jetlerini kullanmasına izin veren anlaşmayı imzaladı 1 yıl ago kaynuka Dünya Ekonomi Medya Teknoloji Trump bağlantılı hisseler DeSantis’in havlu atmasının ardından yükseldi 2 yıl ago kaynuka Bilim/Çevre Dünya Ekonomi Teknoloji Tencent’in Riot Games personelinin yaklaşık %11’ini işten çıkaracak 2 yıl ago kaynuka Bir yanıt yazın Yanıtı iptal etE-posta adresiniz yayınlanmayacak. Gerekli alanlar * ile işaretlenmişlerdirYorum * Ad * E-posta * İnternet sitesi